

╚╦ÖCī”įÆę╗ų▒╩Ūūį╚╗šZčį╠Ä└ĒŅIė“ā╚Ą─ųžę¬čąŠ┐ĘĮŽ“ų«ę╗Ż¼Į³─ĻüĒļSų°╚╦ÖCĮ╗╗ź╝╝ągĄ─▀M▓ĮŻ¼ī”įÆŽĄĮyš²ųØuū▀Ž“īŹļHæ¬ė├ĪŻŲõųąŻ¼ųŪ─▄┐═Ę■ŽĄĮy╩▄ĄĮ┴╦║▄ČÓŲ¾śIė╚Ųõ╩Ūųą┤¾ą═Ų¾śIĄ─ÅVĘ║ĻPūóĪŻųŪ─▄┐═Ę■ŽĄĮyų╝į┌ĮŌøQé„Įy┐═Ę■─Ż╩ĮąĶę¬┤¾┴┐╚╦┴”Ą─ĀŅørŻ¼į┌╣Ø╝s╚╦┴”Ą─═¼ĢrŻ¼╩╣Ą├╚╦╣ż┐═Ę■į┌ßśī”╠žäeå¢Ņ}╗“š▀╠žäeė├æ¶Ģr─▄ē“╠ß╣®Ė³Ė▀┘|┴┐Ą─Ę■䚯¼Å─Č°īŹ¼FĪ░ųŪ─▄┐═Ę■ + ╚╦╣ż┐═Ę■Ī▒į┌Ę■äšą¦┬╩║═Ę■äš┘|┴┐ā╔éĆŠSČ╚╔ŽĄ─š¹¾w╠ß╔²ĪŻĮ³─ĻüĒŻ¼įSČÓųą┤¾ą═╣½╦ŠČ╝ęčĮøśŗĮ©┴╦ūį╝║Ą─ųŪ─▄┐═Ę■¾wŽĄŻ¼└²╚ńĖ╗╩┐═©Ą─ FRAPĪ󊮢|Ą─ JIMI ║═░ó└’░═░═Ą─ AliMe Ą╚ĪŻ
ųŪ─▄┐═Ę■ŽĄĮyĄ─śŗĮ©ąĶę¬ę└═ąė┌ąąśIöĄō■▒│Š░Ż¼▓ó╗∙ė┌║Ż┴┐ų¬ūR╠Ä└Ē║═ūį╚╗šZčį└ĒĮŌĄ╚ŽÓĻP╝╝ągĪŻ│§┤·ųŪ─▄┐═Ę■ŽĄĮyų„ę¬├µī”śIäšā╚╚▌Ż¼ßśī”Ė▀ŅlĄ─śIäšå¢Ņ}▀Mąą╗žÅ═ĮŌøQŻ¼┤╦▀^│╠ę└┘ćė┌śIäšīŻ╝ęī”Ė▀ŅlśIäšå¢Ņ}┤░ĖĄ─£╩┤_š¹└ĒŻ¼ų„ꬥ─╝╝ąg³cį┌ė┌Š½£╩Ą─ė├æ¶å¢Ņ}║═ų¬ūR³cų«ķgĄ─╬─▒ŠŲź┼õ─▄┴”ĪŻą┬ą═Ą─ųŪ─▄┐═Ę■ŽĄĮyīóĘ■äšĘČć·Č©┴x×ķĘ║śIäšł÷Š░Ż¼│²┴╦ĮŌøQ╠Ä└Ē║╦ą─Ą─Ė▀ŅlśIäšå¢Ņ}Ż¼ųŪ─▄ī¦┘Å─▄┴”Ī󚎥KŅA£y─▄┴”ĪóųŪ─▄šZ┴──▄┴”Īó╔·╗Ņų·└Ē╣”─▄ęį╝░╔·╗ŅŖ╩śĘĮ╗╗źĄ╚ĘĮ├µĄ─ąĶŪ¾ę▓═¼śė▒╗ųžęĢ║═║Ł╔wĪŻŲõųąŻ¼ŪķĖą─▄┴”ū÷×ķŅÉ╚╦─▄┴”Ą─ųžę¬¾w¼FŻ¼ęčĮøį┌ųŪ─▄┐═Ę■ŽĄĮyĄ─Ė„éĆŠSČ╚Ą─ł÷Š░ųą▒╗īŹļHæ¬ė├Ż¼▓óŪęī”ŽĄĮyŅÉ╚╦─▄┴”Ą─╠ß╔²ŲĄĮ┴╦ų┴ĻPųžę¬Ą─ū„ė├ĪŻ
ę╗ ųŪ─▄┐═Ę■ŽĄĮyųąŪķĖąĘų╬÷╝╝ąg╝▄śŗ

łD 1Ż║ųŪ─▄┐═Ę■ŽĄĮyųąĄ─ŪķĖąĘų╬÷╝╝ąg╝▄śŗ
łD 1 Įo│÷┴╦ĮøĄõĄ─╚╦ÖCĮY║ŽĄ─ųŪ─▄┐═Ę■─Ż╩ĮŻ¼ė├æ¶─▄ē“═©▀^ī”įÆĄ─ĘĮ╩ĮŻ¼Įė╩▄üĒūįÖCŲ„╚╦╗“š▀╚╦╣ż┐═Ę■Ą─Ę■䚯¼▓óŪęį┌Įė╩▄ÖCŲ„╚╦Ę■䚥─▀^│╠ųąŻ¼─▄ē“└¹ė├ųĖ┴ŅĄ─ĘĮ╩Į╗“š▀ÖCŲ„╚╦ūįäėūRäeĄ─ĘĮ╩Į╠°▐DĄĮ╚╦╣ż┐═Ę■ĪŻį┌╔Ž╩÷Ą─═Ļš¹┐═Ę■─Ż╩ĮųąŻ¼ŪķĖąĘų╬÷╝╝ągęčĮø▒╗īŹļHæ¬ė├į┌ČÓéĆŠSČ╚Ą──▄┴”ų«╔ŽĪŻ
Č■ ė├æ¶ŪķĖąÖz£y
1 ė├æ¶ŪķĖąÖz£y─Żą═ĮķĮB
ė├æ¶ŪķĖąÖz£y╩Ū║▄ČÓŪķĖąŽÓĻPæ¬ė├Ą─╗∙ĄA║═║╦ą─ĪŻį┌▒Š╬─ųąŻ¼╬ęéā╠ß│÷ę╗ĘN╝»│╔į~šZ┴x╠žš„ĪóČÓį¬į~ĮMšZ┴x╠žš„║═Šõūė╝ēšZ┴x╠žš„Ą─ŪķĖąĘųŅÉ─Żą═Ż¼ė├ė┌ūRäeųŪ─▄┐═Ę■ŽĄĮyė├æ¶ī”įÆųą░³║¼Ą─Ī░ų°╝▒Ī▒ĪóĪ░ÜŌæŹĪ▒║═Ī░ĖąųxĪ▒Ą╚ŪķĖąĪŻĻPė┌▓╗═¼īė┤╬šZ┴x╠žš„Ą─│ķ╚Ī╝╝ągŻ¼ŽÓĻP╣żū„ųąęčĮøČÓėą╠ß╝░Ż¼╬ęéāīó▓╗═¼īė┤╬Ą─šZ┴x╠žš„ĮY║ŽĄĮę╗ŲŻ¼─▄ē“ėąą¦╠ß╔²ūŅĮKĄ─ŪķŠwūRäeą¦╣¹ĪŻłD 2 Įo│÷┴╦įōŪķĖąĘųŅÉ─Żą═Ą─╝▄śŗłDĪŻ
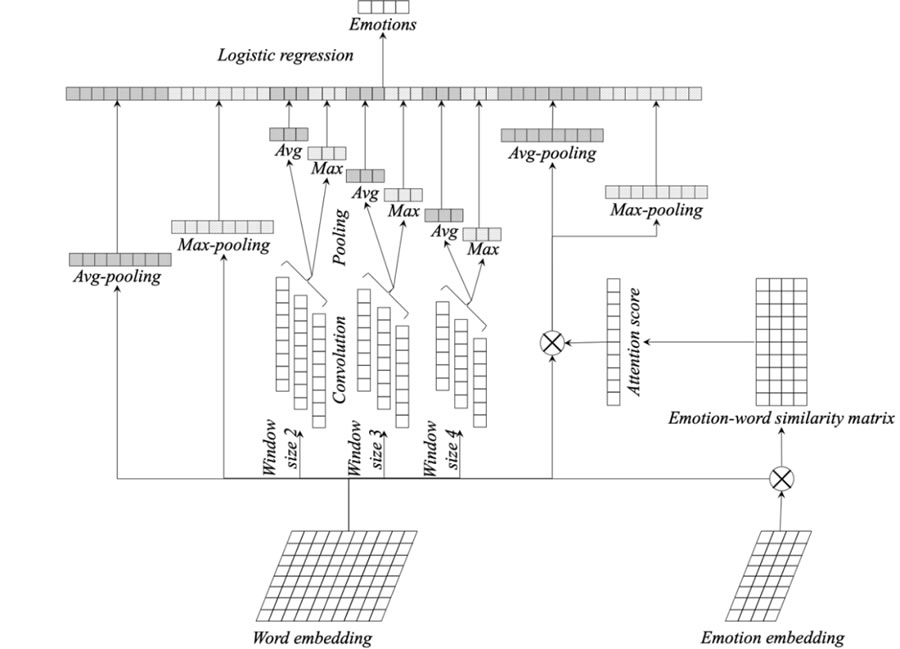
łD 2Ż║ųŪ─▄┐═Ę■ŽĄĮyųąĄ─ė├æ¶ŪķĖąÖz£y─Żą═
2 Šõūė╝ēšZ┴x╠žš„│ķ╚Ī
Shen Ą╚╚╦[3]╠ß│÷ SWEM ─Żą═Ż¼įō─Żą═īó║åå╬Ą─│ž╗»▓▀┬įæ¬ė├ė┌į~ŪČ╚ļŽ“┴┐Ż¼īŹ¼FŠõūė╝ēäeĄ─šZ┴x╠žš„│ķ╚ĪŻ¼▓óŪę╗∙ė┌┤╦ŅÉ╠žš„▀Mąąė¢ŠÜĄ├ĄĮĄ─ĘųŅÉ─Żą═║═╬─▒ŠŲź┼õ─Żą═─▄ē“Ą├ĄĮ┼cĮøĄõĄ─ŠĒĘe╔±ĮøŠWĮjŅÉ─Żą═║═裣h╔±ĮøŠWĮjŅÉ─Żą═Äū║§│ųŲĮĄ─īŹ“׹¦╣¹ĪŻ
į┌╬ęéāĄ──Żą═ųąŻ¼╬ęéā└¹ė├ SWEM ─Żą═Ą─╠žš„│ķ╚Ī─▄┴”Ż¼½@╚Īė├æ¶å¢Ņ}Ą─Šõūė╝ēäešZ┴x╠žš„Ż¼▓óīóŲõė├ė┌ī”ė├æ¶å¢Ņ}Ą─ŪķĖąĘųŅÉ─Żą═ųąĪŻ
3 ČÓį¬į~ĮMšZ┴x╠žš„│ķ╚Ī
é„ĮyĄ─ CNN ─Żą═į┌║▄ČÓŪķørŽ┬▒╗ė├ė┌│ķ╚Ī n į¬į~ĮMšZ┴x╠žš„Ż¼Ųõųą n ╩Ūę╗éĆūā┴┐Ż¼▒Ē╩ŠŠĒĘe┤░┐┌┤¾ąĪĪŻį┌▒Š╬─ųąŻ¼╬ęéāĖ∙ō■Įø“×īó n ĘųäeįOų├×ķ 2Īó3 ║═ 4Ż¼▓óŪęßśī”├┐ę╗ĘN┤░┐┌┤¾ąĪŻ¼╬ęéāĘųäeįOų├ 16éĆ ŠĒĘe║╦Ż¼ęįė├ė┌Å─įŁ╩╝Ą─į~Ž“┴┐ŠžĻćųą│ķ╚ĪžSĖ╗Ą─ n į¬į~ĮMšZ┴xą┼ŽóĪŻ
4 į~╝ēäešZ┴x╠žš„│ķ╚Ī
╬ęéā└¹ė├ LEAM ─Żą═ [1] │ķ╚Īį~╝ēäeĄ─šZ┴x╠žš„ĪŻLEAM ─Żą══¼Ģrīóį~šZ║═ŅÉäeś╦║×▀Mąą═¼ŠSČ╚šZ┴x┐šķgĄ─ŪČ╚ļ╩Į▒Ē╩ŠŻ¼▓óŪę╗∙ė┌įō▒Ē╩Š▀Mąą╬─▒ŠĘųŅÉ╚╬䚥─īŹ¼FĪŻLEAM └¹ė├ŅÉäeś╦║ץ─▒Ē╩ŠŻ¼į÷╝ė┴╦į~šZ║═ś╦║×ų«ķgĄ─šZ┴xĮ╗╗źŻ¼ęį┤╦▀_ĄĮī”į~╝ēäešZ┴xą┼ŽóĖ³╔Ņīė┤╬Ą─┐╝æ]ĪŻłD 3Ż©2Ż®ųąĮo│÷┴╦ŅÉäeś╦║×║═į~šZų«ķgĄ─šZ┴xĮ╗╗źĄ─łD╩ŠŻ¼▓óŪęĮo│÷┴╦ LEAM ─Żą═┼cé„Įy─Żą═ų«ķgĄ─ī”▒╚ĪŻ

łD 3Ż║LEAM─Żą═ųąį~šZ║═ŅÉäeś╦║×ų«ķgĄ─šZ┴xĮ╗╗źŻ©é„ĮyĘĮĘ©║═LEAM─Żą═Ą─ī”▒╚Ż®
ūŅ║¾Ż¼▓╗═¼╝ēäeĄ─šZ┴x╠žš„Ģ■į┌▒╗║Ž▓óį┌ę╗Ųų«║¾Ż¼▌ö╚ļĄĮš¹éĆ─Żą═Ą─ūŅ║¾ę╗īėŻ¼ė╔▀ē▌ŗ╗žÜw─Żą═▀MąąūŅĮKĄ─ĘųŅÉė¢ŠÜĪŻ
▒Ē 1 ųąĮo│÷┴╦╬ęéā╠ß│÷Ą─╝»│╔╩Į─Żą═║═╚²éĆų╗┐╝æ]å╬éĆīė┤╬╠žš„Ą─ī”▒╚─Żą═ų«ķgĄ─ŠĆ╔ŽšµīŹįu£yą¦╣¹ī”▒╚ĮY╣¹ĪŻ

▒Ē 1Ż║╝»│╔─Żą═║═╚²ĘN baseline ─Żą═Ą─ą¦╣¹ī”▒╚
╚² ė├æ¶ŪķĖą░▓ōß
1 ė├æ¶ŪķŠw░▓ōßš¹¾w┐“╝▄ĮķĮB
▒Š╬─ųą╠ß│÷Ą─ė├æ¶ŪķŠw░▓ōß┐“╝▄░³└©ļxŠĆ▓┐Ęų║═į┌ŠĆ▓┐ĘųŻ¼╚ńłD 4 ╦∙╩ŠĪŻ

łD 4Ż║ė├æ¶ŪķŠw░▓ōßš¹¾w┐“╝▄
ļxŠĆ▓┐Ęų
╩ūŽ╚ąĶę¬ī”ė├æ¶Ą─ŪķŠw▀MąąūRäeĪŻ┤╦╠Ä╬ęéā▀x╚Ī┴╦ąĶę¬░▓ōߥ─ė├æ¶│ŻęŖĄ─Ų▀ĘNŪķŠw▀MąąūRäeŻ¼╦³éā╩Ū║”┼┬Īó╚Ķ┴RĪó╩¦═¹Īó╬»Ū³Īóų°╝▒ĪóÜŌæŹ║═ĖąųxĪŻ
Ųõ┤╬Ż¼╬ęéāī”ė├æ¶å¢Ņ}ųą░³║¼Ą─ų„Ņ}ā╚╚▌▀MąąūRäeŻ¼┤╦╠Äė╔īŻķTĄ─śIäšīŻ╝ę┐éĮY┴╦ė├æ¶│ŻęŖĄ─ 35 ĘNų„Ņ}▒Ē▀_ā╚╚▌Ż¼░³└©Ī░▒¦į╣Ę■äš┘|┴┐Ī▒║═Ī░Ę┤ü╬’┴„╠½┬²Ī▒Ą╚ĪŻų„Ņ}ūRäe─Żą═Ż¼╬ęéā╩╣ė├┼cŪķŠwūRäe═¼śėĄ─ĘųŅÉ─Żą═įOėŗĪŻ
ų¬ūRśŗĮ©╩Ūßśī”ę╗ą®ė├æ¶▒Ē▀_ā╚╚▌Ė³Š▀¾wĄ─ŪķørŻ¼š¹└ĒŲõųąĖ▀Ņl│÷¼FĄ─▓óŪęąĶę¬▀Mąą░▓ōߥ─ė├æ¶å¢Ņ}ĪŻ▀@ą®Š▀¾wĄ─ė├æ¶å¢Ņ}ų«╦∙ęįø]ėą║Ž▓óĄĮ╔Ž╩÷Ą─ų„Ņ}ŠSČ╚▀MąąĮyę╗╠Ä└ĒŻ¼╩Ūę“×ķų„Ņ}ŠSČ╚Ą─╠Ä└Ē▀Ć╩ŪŽÓī”┤ų┴ŻČ╚ę╗ą®Ż¼╬ęéāŽŻ═¹ßśī”▀@ą®Ė▀ŅlĄ─Ė³Š█Į╣Ą─å¢Ņ}Ż¼═¼śė▀MąąĖ³Š█Į╣Ą─░▓ōß╗žÅ═Ż¼īŹ¼FĖ³║├Ą─╗žÅ═ą¦╣¹ĪŻ
ßśī”ŪķŠwŠSČ╚ĪóĪ░ŪķŠw + ų„Ņ}Ī▒ŠSČ╚║═Ė▀Ņlė├æ¶å¢Ņ}ŠSČ╚Ż¼śIäšīŻ╝ęĘųäeš¹└Ē┴╦▓╗═¼┴ŻČ╚Ą─░▓ōß╗žÅ═įÆągĪŻ╠žäeĄžŻ¼į┌Ė▀Ņlė├æ¶å¢Ņ}ŠSČ╚Ż¼╬ęéāīó├┐ę╗éĆĪ░å¢Ņ} - ╗žÅ═Ī▒┤Ņ┼õĘQ×ķę╗Ślų¬ūRĪŻ
į┌ŠĆ▓┐Ęų
╗∙ė┌ų¬ūRĄ─░▓ōß╩Ūßśī”ĦėąŠ▀¾wŪķŠwā╚╚▌▒Ē▀_Ą─ė├æ¶▀Mąą░▓ō߯¼į┌┤╦╬ęéā╩╣ė├┴╦ę╗ĘN╬─▒ŠŲź┼õ─Żą═üĒįuārė├æ¶å¢Ņ}┼c╬ęéāš¹└Ē║├Ą─ų¬ūRųąĄ─å¢Ņ}Ą─Ųź┼õČ╚ĪŻ╚ń╣¹į┌╬ęéāš¹└Ē║├Ą─ų¬ūRųą┤µį┌┼c«öŪ░ė├æ¶▌ö╚ļå¢Ņ}ęŌ╦╝ĘŪ│ŻŽÓĮ³Ą─å¢Ņ}Ż¼ätī”æ¬Ą─╗žÅ═ų▒ĮėĘĄ╗žĮoė├æ¶ĪŻ
╗∙ė┌ŪķŠw║═ų„Ņ}Ą─ŪķĖą╗žÅ═Ż¼╩ŪųĖ═¼Ģr┐╝æ]ė├æ¶▒Ē▀_ā╚╚▌ųą░³║¼Ą─ŪķŠw║═ų„Ņ}ą┼ŽóŻ¼ĮoėĶė├æ¶║Ž▀mĄ─ŪķĖą╗žÅ═ĪŻŽÓ▒╚ė┌╗∙ė┌ų¬ūRĄ─░▓ō߯¼┤╦ĘNĘĮ╩ĮĄ─╗žÅ═Ģ■Ė³╝ėĄ─Ę║╗»ę╗ą®ĪŻ
╗∙ė┌ŪķŠwŅÉäeĄ─ŪķĖą╗žÅ═Ż¼╩Ūų╗┐╝æ]ė├æ¶▒Ē▀_ā╚╚▌ųąĄ─ŪķŠwę“╦žČ°ī”ė├æ¶▀MąąŽÓæ¬Ą─░▓ōß╗žÅ═ĪŻ┤╦╗žÅ═ĘĮ╩Į╩Ū╔Ž╩÷ā╔ĘN╗žÅ═ĘĮ╩ĮĄ─ča│õ║═ČĄĄūŻ¼═¼Ģr╗žÅ═Ą─ā╚╚▌ę▓Ģ■Ė³╝ėĄ─═©ė├ĪŻ

łD 5Ż║ė├æ¶ŪķŠw░▓ōß╩Š└²
łD 5 Įo│÷┴╦į┌ŠĆŪķĖą░▓ōߥ─╚²éĆ╩Š└²Ż¼Ęųäeī”æ¬╔Ž╩÷Ą─╚²ĘN▓╗═¼īė├µĄ─╗žÅ═ÖCųŲĪŻ ▒Ē 2Ż║ąĶę¬░▓ōߥ─ŪķĖąĘųŅÉą¦╣¹ī”▒╚

▒Ē 2 Įo│÷┴╦ßśī”ąĶę¬░▓ōßŪķĖąĄ─ĘųŅÉ─Żą═ą¦╣¹ī”▒╚Ż¼░³└©├┐ĘNŪķĖąŅÉäeĄ─å╬¬Üą¦╣¹ęį╝░ūŅĮKĄ─š¹¾wą¦╣¹ĪŻ▒Ē 3 Įo│÷┴╦ßśī”ų„Ņ}Ą─ĘųŅÉ─Żą═ą¦╣¹ī”▒╚ĪŻ▒Ē4Įo│÷┴╦ßśī”ÄūĘNžō├µŪķĖąŻ¼į÷╝ė┴╦ŪķŠw░▓ōßų«║¾Ż¼ė├æ¶ØMęŌČ╚Ą─╠ß╔²ą¦╣¹ĪŻ▒Ē 5 Įo│÷┴╦ßśī”Ėą╝ż▀@ĘNŪķĖąŻ¼į÷╝ė┴╦ŪķŠw░▓ōßų«║¾Ż¼ė├æ¶ØMęŌČ╚Ą─╠ß╔²ą¦╣¹ĪŻ ▒Ē 3Ż║ų„Ņ}ĘųŅÉą¦╣¹ī”▒╚ ▒Ē 4Ż║žō├µŪķŠw░▓ōßī”ė├æ¶ØMęŌČ╚Ą─ą¦╣¹ī”▒╚ ▒Ē 5Ż║Ėą╝żŪķĖą░▓ōßī”ė├æ¶ØMęŌČ╚Ą─ą¦╣¹ī”▒╚

╦─ ŪķĖą╔·│╔╩ĮšZ┴─
1 ŪķĖą╔·│╔╩ĮšZ┴──Żą═
łD 6 ųąĮo│÷┴╦ųŪ─▄┐═Ę■ŽĄĮyųąĄ─ŪķĖą╔·│╔╩ĮšZ┴─Ą──Żą═łDĪŻłDųąŻ¼source RNN ŲĄĮ┴╦ŠÄ┤aŲ„Ą─ū„ė├Ż¼īóį┤ą“┴ąsė│╔õ×ķę╗éĆųąķgšZ┴xŽ“┴┐ CŻ¼Č° target RNN ū„×ķĮŌ┤aŲ„Ż¼ät─▄ē“Ė∙ō■šZ┴xŠÄ┤a C ęį╝░╬ęéāįOČ©Ą─ŪķŠw▒Ē╩Š E ║═ų„Ņ}▒Ē╩Š TŻ¼ĮŌ┤aĄ├ĄĮ─┐ś╦ą“┴ą yĪŻ┤╦╠ÄĄ─ s ║═ yŻ¼Ęųäeī”æ¬łDųąė╔į~šZą“┴ąĮM│╔Ą─Ī░Į±╠ņą─Ūķ║▄║├Ī▒║═Ī░║├ķ_ą─čĮŻĪĪ▒ā╔éĆŠõūėĪŻ
═©│ŻŻ¼×ķ┴╦╩╣ĮŌ┤aŲ„─▄ē“▒Ż┴¶üĒūįŠÄ┤aŲ„Ą─ą┼ŽóŻ¼ŠÄ┤aŲ„Ą─ūŅ║¾ę╗éĆĀŅæBīóū„×ķ│§╩╝ĀŅæBé„▀fĮoĮŌ┤aŲ„ĪŻ═¼ĢrŻ¼ŠÄ┤aŲ„║═ĮŌ┤aŲ„═∙═∙╩╣ė├▓╗═¼Ą─ RNN ŠWĮjė├ęį▓Č½@墊õ║═╗žÅ═Šõ▓╗═¼Ą─▒Ē▀_─Ż╩ĮĪŻŠ▀¾wĄ─ėŗ╦Ń╣½╩Į╚ńŽ┬Ż║

ļm╚╗╗∙ė┌ Seq2Seq Ą─ī”įÆ╔·│╔─Żą═╚ĪĄ├┴╦▓╗ÕeĄ─ą¦╣¹Ż¼Ą½╩Ūį┌īŹļHæ¬ė├ųą─Żą═║▄╚▌ęū╔·│╔░▓╚½Ą½╩Ū¤oęŌ┴xĄ─╗žÅ═ĪŻįŁę“į┌ė┌įō─Żą═ųąĄ─ĮŌ┤aŲ„āHāHĮė╩šĄĮŠÄ┤aŲ„ūŅ║¾Ą─ę╗éĆĀŅæB▌ö│÷ CŻ¼▀@ĘNÖCųŲī”╠Ä└ĒķLŲ┌ę└┘湦╣¹▓╗╝čŻ¼ę“×ķĮŌ┤aŲ„Ą─ĀŅæBėøæøļSų°ą┬į~Ą─▓╗öÓ╔·│╔Ģ■ųØu£p╚§╔§ų┴üG╩¦į┤ą“┴ąĄ─ą┼ŽóĪŻŠÅĮŌ▀@éĆå¢Ņ}Ą─ę╗éĆėąą¦ĘĮ╩Į╩Ūę²╚ļūóęŌ┴”ÖCųŲ[2]ĪŻ

łD 6Ż║ųŪ─▄┐═Ę■ŽĄĮyųąĄ─ŪķĖą╔·│╔╩ĮšZ┴──Żą═

2 ŪķĖą╔·│╔╩ĮšZ┴──Żą═ĮY╣¹
─Żą═ė¢ŠÜ═Ļ│╔ų«║¾Ż¼į┌šµīŹĄ─ė├æ¶å¢Ņ}╔Ž▀Mąą£yįćŻ¼ĮY╣¹ė╔śIäšīŻ╝ę▀MąąÖz▓ķŻ¼ūŅĮKĄ─┤░Ė║ŽĖ±┬╩╝s×ķ 72%ĪŻ┴Ē═ŌŻ¼╗žÅ═╬─▒ŠĄ─ŲĮŠ∙ķLČ╚×ķ 8.8 éĆūųŻ¼ĘŪ│ŻĘ¹║Ž░ó└’ąĪ├█šZ┴─ł÷Š░ųąī”╗žÅ═ķLČ╚Ą─ąĶŪ¾ĪŻ▒Ē 6 ųąĮo│÷┴╦▒Š╬──Żą═ AETŻ©Attention-based emotional & topical Seq2Seq modelŻ®┼cé„Įy Seq2Seq ─Żą═Ą─ą¦╣¹ī”▒╚ĪŻī”▒╚ų„ę¬╝»ųąį┌ā╚╚▌║ŽĖ±┬╩ęį╝░╗žÅ═ķLČ╚ā╔éĆĘĮ├µĪŻ╠Ē╝ė┴╦ŪķŠwą┼Žóų«║¾Ż¼╗žÅ═ā╚╚▌▌^ų«é„Įy seq2seq ─Żą═Ģ■Ė³×ķžSĖ╗Ż¼Č°Ę¹║Žė├čąĘų╬÷Ą─Ī░5 - 20ūųĪ▒ūŅ╝čÖCŲ„╚╦šZ┴─╗žÅ═ķLČ╚Ą─ā╚╚▌š╝▒╚ę▓Ģ■┤¾Ę∙į÷╝ėŻ¼ūŅĮK╩╣Ą├š¹¾wĄ─╗žÅ═║ŽĖ±┬╩╠ß╔²├„’@ĪŻ
łD 7 ųąĮo│÷┴╦░ó└’ąĪ├█ŪķŠw╔·│╔╩ĮšZ┴──Żą═į┌ąĪ├█┐šķgųąĄ─æ¬ė├╩Š└²ĪŻłDųąā╔éĆ┤░ĖŠ∙ė╔ŪķŠw╔·│╔╩Į─Żą═Įo│÷Ż¼▓óŪęŻ¼ī”ė┌ė├æ¶╚Ķ┴RÖCŲ„╚╦╠½╔ĄĄ─ė├æ¶▌ö╚ļŻ¼╬ęéāĄ──Żą═┐╔ęįĖ∙ō■įOų├Ą─ī”æ¬║Ž└ĒĄ─įÆŅ}║═ŪķŠwŻ¼«a╔·▓╗═¼Ą─┤░ĖŻ¼žSĖ╗┴╦┤░ĖĄ─ČÓśėąįŻ¼łDųąā╔éĆ┤░ĖŻ¼ät╩Ūė╔Ī«╬»Ū³Ī»║═Ī«▒¦ŪĖĪ»ā╔éĆŪķŠw«a╔·ĪŻ łD 7Ż║ąĪ├█┐šķgųąĄ─ŪķŠw╔·│╔╩ĮšZ┴─æ¬ė├īŹ└²

╬Õ ┐═Ę■Ę■äš┘|Öz
1 ┐═Ę■Ę■äš┘|┴┐å¢Ņ}Č©┴x
▒Š╬─╦∙šfĄ─┐═Ę■Ę■äš┘|Öz╩Ūßśī”╚╦╣ż┐═Ę■į┌║═┐═æ¶ī”įÆĄ─▀^│╠ųą┐╔─▄│÷¼FĄ─┤µį┌å¢Ņ}Ą─Ę■äšā╚╚▌▀MąąÖz£yŻ¼Å─Č°Ė³║├Ąž░l¼F┐═Ę■╚╦åTį┌Ę■äš▀^│╠ųą┤µį┌Ą─å¢Ņ}▓óģfų·┐═Ę■╚╦åT▀MąąĖ─▀MŻ¼▀_ĄĮ╠ßĖ▀┐═Ę■Ę■äš┘|┴┐Ż¼ūŅĮK╠ßĖ▀┐═æ¶ØMęŌČ╚ą¦╣¹ĪŻō■ū„š▀╦∙ų¬Ż¼─┐Ū░▀Ćø]ėą╣½ķ_īŹ¼FĄ─ßśī”┐═Ę■ŽĄĮyųą┐═Ę■Ę■äš┘|┴┐Öz£yĄ─╚╦╣żųŪ─▄ŽÓĻP╦ŃĘ©─Żą═ĪŻ
┼c╚╦ÖCī”įÆ▓╗═¼Ż¼╚╦╣ż┐═Ę■║═┐═æ¶Ą─ī”įÆ▓ó▓╗╩Ūę╗å¢ę╗┤ą╬╩ĮŻ¼Č°╩Ū┐═æ¶║═┐═Ę■Ęųäe─▄ē“▀B└m▌ö╚ļČÓŠõ╬─▒ŠĪŻ╬ęéāĄ──┐ś╦╩ŪÖz£y├┐ę╗Šõ┐═Ę■Ą─įÆągā╚╚▌╩Ūʱ░³║¼Ī░Ž¹śOĪ▒╗“š▀Ī░æBČ╚▓ŅĪ▒ā╔ĘNĘ■äš┘|┴┐å¢Ņ}ĪŻ
2 ┐═Ę■Ę■äš┘|Öz─Żą═
×ķ┴╦Öz£yę╗Šõ┐═æ¶įÆągĄ─Ę■äš┘|┴┐Ż¼╬ęéāąĶę¬┐╝æ]Ųõ╔ŽŽ┬╬─ā╚╚▌Ż¼░³└©ė├æ¶å¢Ņ}║═┐═Ę■įÆągĪŻ╬ęéā┐╝æ]Ą─╠žš„░³└©╬─▒ŠķLČ╚ĪóšfįÆ╚╦ĮŪ╔½║═╬─▒Šā╚╚▌ĪŻŲõųąŻ¼ßśī”╬─▒Šā╚╚▌Ż¼│²┴╦└¹ė├ SWEM ─Żą═ī”┤²Öz£yĄ─«öŪ░┐═Ę■įÆąg▀Mąą╠žš„│ķ╚ĪŻ¼╬ęéā▀Ćī”╔ŽŽ┬╬─ųąĄ─├┐▌åįÆąg▀MąąŪķŠwÖz£yŻ¼░l¼Fė├æ¶ŪķŠwŅÉäe║═┐═Ę■ŪķŠwŅÉäeū„×ķ─Żą═╠žš„Ż¼Č°┤╦╠Ä╩╣ė├Ą─ŪķŠwūRäe─Żą═ę▓╚ńĄ┌ 2 š┬ųą╦∙╩÷ę╗ų┬Ż¼ęÓ▓╗į┘┘ś╩÷ĪŻ┤╦═ŌŻ¼╬ęéā▀Ć┐╝æ]┴╦ā╔ĘNĮYśŗŻ©łD 8 ųą─Żą═ 1 ║═łD 9 ųą─Żą═ 2Ż®ī”╗∙ė┌╔ŽŽ┬╬─ā╚╚▌Ą─╬─▒Šą“┴ąšZ┴x╠žš„▀Mąą│ķ╚ĪĪŻ
ŲõųąŻ¼─Żą═ 1 į┌ī”«öŪ░┐═Ę■įÆąg╝░Ųõ╔ŽŽ┬╬─├┐Šõ╬─▒Š▀Mąą╗∙ė┌ GRU ╗“ LSTM Ą─ŠÄ┤aų«║¾Ż¼ßśī”ŠÄ┤aĮY╣¹Ż¼┐╝æ]└¹ė├š²Ž“║═Ę┤Ž“ GRU ╗“š▀ LSTM Ęųäeī”«öŪ░┤²Öz£y┐═Ę■įÆągĄ─╔Ž╬─║═Ž┬╬─Ą─ŠÄ┤aĮY╣¹▀Mąąį┘┤╬Ą─ą“┴ą╗»ŠÄ┤aŻ¼╚ń┤╦Ą├ĄĮĄ─ā╔éĆą“┴ą╗»ŠÄ┤aĮY╣¹Š∙╩Ūęį«öŪ░įÆąg×ķ╬▓ŠõŻ¼─▄ē“Ė³║├Ą─¾w¼F«öŪ░įÆągĄ─šZ┴xą┼ŽóĪŻ─Żą═ĮYśŗ╚ńłD 8 ╦∙╩ŠĪŻ
┴Ē═ŌŻ¼─Żą═ 2 īó«öŪ░┐═Ę■įÆąg╝░Ųõ╔ŽŽ┬╬─Ą─ŠÄ┤aĮY╣¹Ż¼į┘┤╬░┤ššŪ░║¾Ēśą“▀Mąąš¹¾wĄ─š²Ž“ GRU ╗“ LSTM ŠÄ┤aū„×ķūŅĮKĄ─šZ┴x╠žš„ĪŻ─Żą═ĮYśŗĄ─▓┐Ęųš╣╩Š╚ńłD 9 ╦∙╩ŠĪŻ─Żą═ 1 ┼c─Żą═ 2 ŽÓ▒╚Ż¼─Żą═1Ģ■Ė³╝ė═╣’@«öŪ░┤²Öz£yįÆągĄ─šZ┴xą┼ŽóŻ¼Č°─Żą═ 2 ätĖ³╝ėČÓĄ├¾w¼Fš¹¾w╔ŽŽ┬╬─Ą─ą“┴ą╗»šZ┴xą┼ŽóĪŻ

╬ęéā▒╚▌^ā╔ĘN╔ŽŽ┬╬─šZ┴xą┼Žó│ķ╚Ī─Żą═Ą─ą¦╣¹Ż¼▒Ē7ųąĮo│÷┴╦ī”▒╚ĮY╣¹Ż¼ĮY╣¹’@╩Š─Żą═ 1 Ą─ą¦╣¹ę¬ā×ė┌─Żą═ 2Ż¼┐╔ęŖī”ė┌«öŪ░┤²Öz£yįÆągĄ─šZ┴xą┼Žó┤_īŹąĶę¬ĮoėĶĖ³ČÓĄ─ÖÓųžŻ¼Č°╔ŽŽ┬╬─Ą─šZ┴xą┼Žó┐╔ęįŲĄĮ▌oų·ūRäeĄ─ū„ė├ĪŻ┤╦═ŌŻ¼ų«Ū░╠ߥĮĄ─ GRU ╗“š▀ LSTM ā╔ĘNĘĮĘ©į┌īŹļHĄ──Żą═ė¢ŠÜ▀^│╠ųąŻ¼ą¦╣¹▓Ņäe▓╗┤¾Ż¼Ą½╩Ū GRU ĘĮĘ©ę¬▒╚ LSTM ĘĮĘ©į┌╦┘Č╚╔ŽĖ³┐ņę╗ą®Ż¼ę“┤╦╦∙ėąĄ──Żą═īŹ“×▀^│╠ųąŠ∙╩╣ė├┴╦ GRU ĘĮĘ©ĪŻ
┤╦═ŌŻ¼ģ^äeė┌─Żą═īė├µĄ─ųĖś╦Ęų╬÷Ż¼╬ęéāßśī”─Żą═į┌īŹļHĄ─ŽĄĮyīė├µĄ─ųĖś╦ę▓▀Mąą┴╦ŽÓæ¬Ą─Ęų╬÷Ż¼░³└©┴╦┘|Özą¦┬╩ęį╝░š┘╗ž┬╩ā╔éĆŠSČ╚ĪŻ▀@ā╔éĆųĖś╦Ż¼╬ęéā╩Ūęį─Żą═Ą─ĮY╣¹┼cų«Ū░╝ā╚╦╣ż┘|ÖzĄ─ĮY╣¹▀Mąąī”▒╚Ą├ĄĮĪŻ╚ń▒Ē 8 ųą╦∙╩ŠŻ¼▓╗╣▄╩Ū┘|Özą¦┬╩▀Ć╩Ū┘|ÖzĄ─š┘╗ž┬╩Č╝Ą├ĄĮ┴╦ĘŪ│Ż┤¾Ą─╠ß╔²ĪŻŲõųąŻ¼╚╦╣ż┘|ÖzĄ─š┘╗ž┬╩▒╚▌^Ą═Ą─įŁę“Ż¼╩Ūę“×ķ╚╦╣ż▓╗┐╔─▄Öz£y╦∙ėąĄ─┐═Ę■Ę■äšėøõøĪŻ ▒Ē 8Ż║īŹļHŽĄĮyīė├µĄ──Żą═ųĖś╦įuārĮY╣¹
┴∙ Ģ■įÆØMęŌČ╚ŅA╣└
1 Ģ■įÆØMęŌČ╚
─┐Ū░į┌ųŪ─▄┐═Ę■ŽĄĮyĄ─ąį─▄įu╣└ųĖś╦ųąŻ¼ėąę╗ĒŚūŅ×ķųžę¬Ą─ųĖś╦×ķė├æ¶Ģ■įÆØMęŌČ╚ĪŻČ°ßśī”ųŪ─▄┐═Ę■ŽĄĮyųąĄ─ė├æ¶Ģ■įÆØMęŌČ╚ūįäėŅA╣└Ą─╣żū„Ż¼ō■ū„š▀╦∙ų¬▀Ćø]ėąŽÓĻPĄ─蹊┐│╔╣¹ĪŻ
ßśī”ųŪ─▄┐═Ę■ŽĄĮyųąĄ─Ģ■įÆØMęŌČ╚ŅA╣└ł÷Š░Ż¼╬ęéā╠ß│÷┴╦Ģ■įÆØMęŌČ╚Ęų╬÷─Żą═Ż¼┐╔ęįĖ³║├Ą─Ę┤欫öŪ░ė├æ¶ī”ųŪ─▄┐═Ę■Ą─ØMęŌČ╚│╠Č╚ĪŻė╔ė┌▓╗═¼ė├æ¶┤µį┌įuārś╦£╩▓Ņ«ÉŻ¼Ģ■┤µį┌┤¾┴┐Ģ■įÆā╚╚▌ĪóĢ■įÆ┤░ĖüĒį┤ĪóĢ■įÆŪķŠwą┼Žó═Ļ╚½ŽÓ═¼Ą─ŪķørŽ┬ŪķŠwŅÉäe▓╗ę╗ų┬Ą─ŪķørĪŻę“┤╦╬ęéā▓╔ė├┴╦ā╔ĘN─Żą═ė¢ŠÜĘĮ╩ĮŻ║Ą┌ę╗ĘN╩Ūė¢ŠÜ─Żą═öM║ŽŪķŠwŅÉäeŻ©ØMęŌĪóę╗░ŃĪó▓╗ØMęŌŻ®Ą─ĘųŅÉ─Żą═Ż¼┴Ēę╗ĘN╩Ūė¢ŠÜ─Żą═öM║ŽĢ■įÆŪķŠwĘų▓╝Ą─╗žÜw─Żą═Ż¼ūŅ║¾ī”ā╔ĘNĘĮ╩Įą¦╣¹ū÷┴╦ī”▒╚ĪŻ
2 Ģ■įÆØMęŌČ╚╠žš„▀x╚Ī
Ģ■įÆØMęŌČ╚─Żą═┐╝æ]┴╦Ė„ĘNŠSČ╚ą┼ŽóŻ║šZ┴xą┼ŽóŻ©ė├æ¶įÆągŻ®ĪóŪķŠwą┼ŽóŻ©═©▀^ŪķĖąÖz£y─Żą═½@╚ĪŻ®Īó┤░ĖüĒį┤ą┼ŽóŻ©╗žÅ═«öŪ░įÆągĄ─┤░ĖüĒį┤Ż®ĪŻ
šZ┴xą┼Žó╩Ūė├æ¶┼cųŪ─▄┐═Ę■Į╗┴„▀^│╠ųą╦∙▒Ē▀_Ą─ā╚╚▌ą┼ŽóŻ¼╦³┐╔ęįÅ─ė├æ¶įÆągųą▌^║├Ę┤æ¬ė├涫öŪ░ØMęŌĀŅørĪŻ╬ęéāį┌─Żą═ųą╩╣ė├Ą─šZ┴xą┼Žó╩ŪųĖĢ■įÆųąĄ─ČÓ▌åįÆągą┼ŽóŻ¼į┌─Żą═╠Ä└Ē▀^│╠ųąŻ¼×ķ┴╦▒ŻūC├┐┤╬─Żą═─▄ē“╠Ä└ĒŽÓ═¼▌å┤╬Ą─įÆągŻ¼╬ęéāīŹ“×ųąų╗╩╣ė├Ģ■įÆųąūŅ║¾4Šõė├æ¶įÆągŻ¼▀xō±┤╦ĘNĘĮ╩ĮĄ─įŁę“╩Ū═©▀^Ģ■įÆöĄō■Ęų╬÷Ż¼ė├æ¶į┌Ģ■įÆ╝┤īóĮY╩°ĢrĄ─šZ┴xą┼Žó┼cš¹¾wĢ■įÆØMęŌ│╠Č╚Ė³×ķŽÓĻPĪŻ▒╚╚ńŻ¼ė├æ¶į┌Ģ■įÆĮY╬▓Ģr▒Ē▀_Ėą╝żų«ŅÉĄ─įÆąg╗∙▒Š▒Ē╩ŠØMęŌŻ¼Č°▒Ē▀_┼·įuų«ŅÉĄ─įÆągät║▄┐╔─▄▒Ē╩Š┴╦ī”Ę■䚥─▓╗ØMĪŻ
ŪķŠwą┼Žóę╗░Ńį┌ė├æ¶ØMęŌČ╚ĘĮ├µŲų°ĘŪ│Ż┤¾Ą─ģó┐╝ū„ė├Ż¼«öė├æ¶│÷¼FæŹ┼ŁĪó╚Ķ┴RĄ╚śOČ╦ŪķŠwĢrŻ¼ė├æ¶Ę┤ü▓╗ØMęŌĄ─Ė┼┬╩Ģ■śO┤¾ĪŻ┤╦╠ÄĄ─ŪķŠwą┼Žó┼cšZ┴xą┼ŽóųąĄ─įÆągę╗ę╗ī”æ¬Ż¼ī”▀x╚ĪĄ─Äū▌åįÆągĘųäe▀MąąŪķŠwūRäeŻ¼½@╚Īī”æ¬Ą─ŪķŠwŅÉäeą┼ŽóĪŻ
┤░ĖüĒį┤ą┼Žó┐╔ęį║▄║├Ą─Ę┤æ¬ė├æ¶ė÷ĄĮ║╬ĘNå¢Ņ}Ż¼ė╔ė┌▓╗═¼Ą─┤░ĖüĒį┤┤·▒Ēų°▓╗═¼śIäšł÷Š░Ż¼▓╗═¼ł÷Š░å¢Ņ}«a╔·Ą─ė├æ¶ØMęŌČ╚ĀŅør▓Ņ«Éąį▒╚▌^├„’@ĪŻ▒╚╚ńŻ¼═ČįVĪóŠSÖÓŅÉĢ■▒╚ū╔įāŅÉĖ³╚▌ęūī¦ų┬ė├æ¶▓╗ØMęŌĪŻ
3 Ģ■įÆØMęŌČ╚─Żą═
į┌▒Š╬─ųąŻ¼╬ęéā╠ß│÷┴╦ĮY║ŽšZ┴xą┼Žó╠žš„ĪóŪķŠwą┼Žó╠žš„║═┤░ĖüĒį┤ą┼Žó╠žš„Ą─Ģ■įÆØMęŌČ╚ŅA╣└─Żą═ĪŻ─Żą═│õĘų┐╝æ]┴╦Ģ■įÆųąĄ─šZ┴xą┼ŽóŻ¼▓óŪę╩╣ė├┴╦öĄō■ē║┐sĄ─ĘĮ╩ĮīóŪķŠwą┼Žó║═┤░ĖüĒį┤ą┼Žó▀Mąą┴╦│õĘų▒Ē▀_ĪŻ─Żą═ĮYśŗ╚ńłD 10 ╦∙╩ŠĪŻ
šZ┴x╠žš„│ķ╚ĪĪŻšZ┴xą┼Žó│ķ╚ĪĘĮ╩Į╩╣ė├īė┤╬ GRU/LSTMŻ¼Ą┌ę╗īė½@╚Ī├┐ŠõįÆĄ─Šõūė▒Ē╩ŠŻ©łD 10 ųą first layer GRU/LSTM ▓┐ĘųŻ®Ż¼Ą┌Č■īėĖ∙ō■Ą┌ę╗īėŠõūė▒Ē╩ŠĮY╣¹½@Ą├ČÓ▌åė├æ¶įÆągĄ─Ė▀ļA▒Ē╩ŠĪŻ
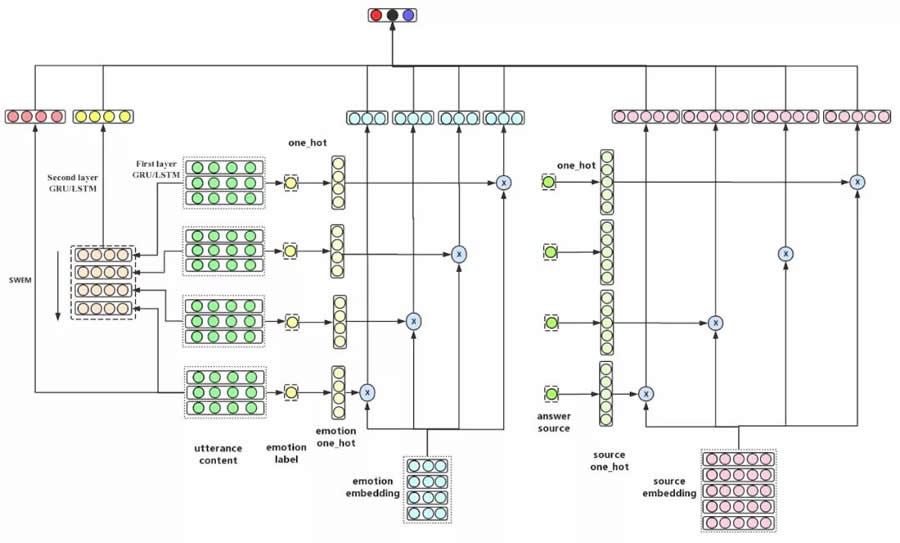
łD 10Ż║ųŪ─▄┐═Ę■ŽĄĮyųąĄ─ė├æ¶Ģ■įÆØMęŌČ╚ŅA╣└─Żą═
Ż©łD 10 ųą second layer GRU/LSTM ▓┐ĘųŻ®Ż¼┤╦╠Ä│õĘų└¹ė├┴╦ė├æ¶įÆągĄ─ą“┴ąą┼ŽóĪŻ│²┤╦ų«═ŌŻ¼▀Ćīó½@╚ĪūŅ║¾ę╗ŠõįÆĄ─ SWEM Šõūė╠žš„Ż¼ęįį÷ÅŖūŅ║¾ę╗ŠõįÆągšZ┴x╠žš„Ą─ė░ĒæĪŻ
ŪķŠw╠žš„│ķ╚ĪŻ║ė╔ė┌½@╚ĪĄ─ŪķŠw╠žš„╩Ū one-hot ŅÉą═Ż¼Č° one-hot ╚▒³c▒╚▌^├„’@Ż¼öĄō■ŽĪ╩ĶŪę¤oĘ©▒Ē╩ŠŪķŠwķgų▒ĮėĻPŽĄĪŻ┤╦╠Ä╬ęéāīW┴Ģę╗éĆŪķŠw embeddingŻ¼üĒĖ³║├Ą─▒Ē▀_ŪķŠw╠žš„ĪŻ
┤░ĖüĒį┤╠žš„│ķ╚ĪŻ║│§╩╝┤░ĖüĒį┤╠žš„═¼śė×ķ one-hot ╠žš„Ż¼Ą½ė╔ė┌┤░ĖĄ─üĒį┤ėą 50ČÓĘNŻ¼ī¦ų┬öĄō■ĘŪ│ŻŽĪ╩ĶŻ¼ę“┤╦ąĶę¬▀Mąą╠žš„ē║┐sŻ¼┤╦╠Ä═¼śė╩╣ė├┴╦ embedding īW┴ĢĘĮ╩ĮŻ¼üĒ▒Ē╩Š┤░ĖüĒį┤╠žš„ĪŻ
─Żą═ŅA£yīėŻ║ĘųäećLįć┴╦ØMęŌČ╚ŅÉäeŅA£y║═ØMęŌČ╚Ęų▓╝ŅA£yŻ¼Ū░š▀ŅA£yī┘ė┌ĘųŅÉ─Żą═Ż¼║¾š▀ī┘ė┌╗žÜw─Żą═ĪŻ
4 Ģ■įÆØMęŌČ╚ŅA╣└īŹ“×ĮY╣¹ łD 11Ż║ė├æ¶Ģ■įÆØMęŌČ╚ŅA╣└ĮY╣¹▒╚▌^
īŹ“×ĮY╣¹╚ńłD 11 ųą╦∙╩ŠĪŻÅ─īŹ“×ĮY╣¹üĒ┐┤ĘųŅÉ─Żą═ØMęŌČ╚ŅA╣└ą¦╣¹▌^▓ŅŻ¼ŲĮŠ∙▒╚īŹļHė├æ¶Ę┤üĖ▀┴╦ 4 éĆ░┘Ęų³cęį╔ŽŻ¼╗žÜw─Żą═┐╔ęį║▄║├Ą─öM║Žė├æ¶Ę┤üĮY╣¹Ż¼Č°Ūę£pąĪ┴╦ąĪśė▒ŠĮY╣¹Ą─š╩ÄŻ¼Ę¹║ŽŅAŲ┌ĪŻ╚ń▒Ē 9 ųą╦∙╩ŠŻ¼╗žÜw─Żą═Ą─Š∙ųĄ┼cė├涚µīŹĘ┤üĄ─ĮY╣¹Ą─▓ŅųĄāH×ķ 0.007Ż¼Č°ĘĮ▓Ņät▒╚ų«Ū░£pąĪ┴╦╚²Ęųų«ę╗Ż¼ūC├„┴╦╗žÜw─Żą═Ą─ėąą¦ąįĪŻ ▒Ē 9Ż║ė├æ¶Ģ■įÆØMęŌČ╚ŅA╣└ĮY╣¹▒╚▌^
Ų▀ ┐éĮY
▒Š╬─┐éĮY┴╦─┐Ū░ųŪ─▄┐═Ę■ŽĄĮyųąŪķĖąĘų╬÷─▄┴”Ą─ę╗ą®īŹļHæ¬ė├ł÷Š░ęį╝░ŽÓæ¬Ą──Żą═ĮķĮB║═ą¦╣¹š╣╩ŠĪŻļm╚╗ŪķĖąĘų╬÷─▄┴”ęčĮøØB═ĖĄĮ┴╦ųŪ─▄┐═Ę■ŽĄĮy╚╦ÖCī”įÆ▀^│╠Ą─Ė„éĆŁh╣ØųąŻ¼Ą½╩Ū─┐Ū░ę▓ų╗─▄╦Ń╩Ūę╗éĆ┴╝║├ćLįćĄ─ķ_╩╝Ż¼Ųõį┌ųŪ─▄┐═Ę■ŽĄĮyĄ─ŅÉ╚╦─▄┴”śŗĮ©▀M│╠ųą▀ĆąĶę¬░lō]Ė³┤¾Ą─ū„ė├ĪŻ
 |
| ╔╠ė├ÖCŲ„╚╦ Disinfection Robot š╣ÅdÖCŲ„╚╦ ųŪ─▄└¼╗°šŠ ▌å╩ĮÖCŲ„╚╦Ąū▒P ėŁ┘eÖCŲ„╚╦ ęŲäėÖCŲ„╚╦Ąū▒P ųvĮŌÖCŲ„╚╦ ūŽ═ŌŠĆŽ¹ČŠÖCŲ„╚╦ ┤¾Ų┴ÖCŲ„╚╦ ņF╗»Ž¹ČŠÖCŲ„╚╦ Ę■äšÖCŲ„╚╦Ąū▒P ųŪ─▄╦═▓═ÖCŲ„╚╦ ņF╗»Ž¹ČŠÖC ÖCŲ„╚╦OEM┤·╣żÅS Ž¹ČŠÖCŲ„╚╦┼┼├¹ ųŪ─▄┼õ╦═ÖCŲ„╚╦ łDĢ°^ÖCŲ„╚╦ ī¦ę²ÖCŲ„╚╦ ęŲäėŽ¹ČŠÖCŲ„╚╦ ī¦į\ÖCŲ„╚╦ ėŁ┘eĮė┤²ÖCŲ„╚╦ Ū░┼_ÖCŲ„╚╦ ī¦ė[ÖCŲ„╚╦ ŠŲĄĻ╦═╬’ÖCŲ„╚╦ įŲ█E┐Ų╝╝ØÖÖCŲ„╚╦ įŲ█EŠŲĄĻÖCŲ„╚╦ ųŪ─▄ī¦į\ÖCŲ„╚╦ |



